On December 21 2011, we released IPython 0.12 after an intense 4 1/2 months of development. Along with a number of new features and bug fixes, the main highlight of this release is our new browser-based interactive notebook: an environment that retains all the features of the familiar console-based IPython but provides a cell-based execution workflow and can contain not only code but any element a modern browser can display. This means you can create interactive computational documents that contain explanatory text (including LaTeX equations rendered in-browser via MathJax), results of computations, figures, video and more. These documents are stored in a version-control-friendly JSON format that is easy to export as a pure Python script, reStructuredText, LaTeX or HTML.
For the IPython project this was a major milestone, as we had wanted for years to have such a system, and it has generated a fair amount of interest online. In particular, on our mailing list a user asked us about the relationship between this effort and the well-known and highly capable Sage Notebook. In responding to the question, I ended up writing up a fairly detailed retrospective of our path to get to the IPython notebook, and it seemed like a good idea to put this up as a blog post to encourage discussion beyond the space of a mailing list, so here it goes (the original email that formed the base of this post, in case anyone is curious about the context).
The question that was originally posed by Oleg Mikulchenklo was: What is the relation and comparison between the IPython notebook and the Sage notebook? Can someone provide motivation and roadmap for the IPython notebook as an alternative to the Sage notebook? I'll try to answer that now...
Early efforts: 2001-2005
Let me provide some perspective on this, since it's a valid question that is probably in the minds of others as well. This is a long post, but I'm trying to do justice to over 10 years of development, multiple interactions between the two projects and the contributions of many people. I apologize in advance to anyone I've forgotten, and please do correct me in the comments, as I want to have a full record that's reasonably trustworthy.
Let's go back to the beginning: when I started IPython in late 2001, I was a graduate student in physics at CU Boulder, and had used extensively first Maple, then Mathematica, both of which have notebook environments. I also used Pascal (earlier) then C/C++, but those two (plus IDL for numerics) were the interactive environments that I knew well, and my experience with them shaped my views on what a good system for everyday scientific computing should look like. In particular, I was a heavy user of the Mathematica notebooks and liked them a lot.
I started using Python in 2001 and liked the language, but its interactive prompt felt like a crippled toy compared to the systems mentioned above or to a Unix shell. When I found out about sys.displayhook, I realized that by putting in a callable object, I would be able to hold state and capture previous results for reuse. I then wrote a python startup file to provide these features and some other niceties such as loading Numeric and Gnuplot, giving me a 'mini-mathematica' in Python (femto- might be a better description, in fairness). Thus was my 'ipython-0.0.1' born, a mere 259 lines to be loaded as $PYTYHONSTARTUP.
I also read an article that mentioned two good interactive systems for Python, LazyPython and IPP, not surprisingly also created by scientists. I say this because the natural flow of scientific computing pretty much mandates a solid interactive environment, so while other Python users and developers may like having occasional access to interactive facilities, scientists more or less demand them. I contacted their authors, Nathan Gray and Janko Hauser, seeking to join forces to create IPython; they were both very gracious and let me use their code, but didn't have the time to participate in the effort. As any self-respecting graduate student with a dissertation deadline looming would do, I threw myself full-time into building the first 'real' IPython by merging my code with both of theirs (eventually I did graduate, by the way).
The point of this little trip down memory lane is to show how from the very beginning, Mathematica and its notebooks (and the Maple worksheets before) were in my mind as the ideal environment for daily scientific work. In 2005 we had two Google SoC students and we took a stab at building, using Wx, a notebook system. Robert Kern then put some more work into the problem, but unfortunately that prototype never really became fully usable.
Sage bursts into the scene
In early 2006, William Stein organized the first Sage Days at UCSD and invited me; William and I had been in touch since 2005 as he was using IPython for the Sage terminal interface. I suggested Robert Kern come as well, and he demoed the notebook prototype he had at that point. It was very clear that the system wasn't production ready, and William was already starting to think about a notebook-like system for Sage as well. Eventually he started working on a browser-based system, and by Sage Days 2 in October 2006, as shown by the coding sprint topics, the Sage notebook was already usable.
For Sage, going at it separately was completely reasonable and justified: we were moving slowly and by that point we weren't even convinced the Wx approach would go anywhere. William is a force of nature and was trying to get Sage to be very usable very fast, so building something integrated for his needs was certainly the right choice.
We continued slowly working on IPython, and actually had another attempt at a notebook-type system in 2006-2007. By that point Brian Granger and Min Ragan-Kelley had come on board and we had built the Twisted-based parallel tools. Using this, Min got a notebook prototype working using an SQL/SQLAlchemy backend. We had the opportunity to work on many of these ideas during a workshop on Interactive Parallel Computation that William and I co-organized (along with others). Like Sage, this prototype used a browser for the client but it tried to retain the 'IPython experience', something the Sage notebook didn't provide.
Keeping the IPython experience in the notebook
This is a key difference of our approach and the Sage notebook, so it' worth clarifying what I mean, the key point being the execution model and its relation to the filesystem. The Sage notebook took the route of using the filesystem for notebook operations, so you can't meaningfully use 'ls' in it or move around the filesystem yourself with 'cd', because Sage will always execute your code in hidden directories with each cell actually being a separate subdirectory. This is a perfectly valid approach and has a number of very good consequences for the Sage notebook, but it is also very different from the IPython model where we always keep the user very close to the filesystem and OS. For us, it's really important that you can access local scripts, use %run, see arbitrary files conveniently, etc., as these are routine needs in data analysis and numerical simulation.
Furthermore, we wanted a notebook that would provide the entire IPython experience, meaning that magics, aliases, syntax extensions and all other special IPython features worked the same in the notebook and terminal. The Sage notebook reimplemented some of these things in its own way: they reused the % syntax but it has a different meaning, they took some of the IPython introspection code and built their own x?/?? object introspection system, etc. In some cases it's almost like IPython but in others the behavior is fairly different; this is fine for Sage but doesn't work for us.
So we continued with our own efforts, even though by then the Sage notebook was fairly mature. For a number of reasons (I honestly don't recall all the details), Min's browser-based notebook prototype also never reached production quality.
Breaking through our bottleneck and ZeroMQ
Eventually, in the summer of 2009 we were able to fund Brian to work full-time on IPython, thanks to Matthew Brett and Jarrod Millman, with resources from the NiPy project. Brian could then dig into the heart of the beast, and attack the fundamental problem that made IPython development so slow and hard: the fact that the main codebase was an outgrowth of that original merge from 2001 of my hack, IPP and LazyPython, by now having become an incomprehensible and terribly interconnected mess with barely any test suite. Brian was able to devote a summer full-time to dismantling these pieces and reassembling them so that they would continue to work as before (with only minimal regressions), but now in a vastly more approachable and cleanly modularized codebase.
This is where early 2010 found us, and then zerendipity struck: while on a month-long teaching trip to Colombia I read an article about ZeroMQ and talked to Brian about it, as it seemed to provide the right abstractions for us with a simpler model than Twisted. Brian then blew me away, coming back in two days with a new set of clean Cython-based bindings: we now had pyzmq! It became clear that we had the right tools to build a two-process implementation of IPython that could give us the 'real IPython' but communicating with a different frontend, and this is precisely what we wanted for cleaner parallel computing, multiprocess clients and a notebook.
When I returned from Colombia I had a free weekend and drove down from Berkeley to San Luis Obispo. Upon arriving at Brian's place I didn't even have zeromq installed nor had I read any docs about it. I installed it, and Brian simply told me what to type in IPython to import the library and open a socket, while he had another one open on his laptop. We then started exchanging messages from our IPython sessions. The fact that we could be up and running this fast was a good sign that the library was exactly what we wanted. We coded frantically in parallel: one of us wrote the kernel and the other the client, and we'd debug one of them while leaving the other running in the meantime. It was the perfect blend of pair programming and simultaneous development, and in just two days we had a prototype of a python shell over zmq working, proving that we could indeed build everything we needed. Incidentally, that code may still be useful to someone wanting to understand our basic ideas or how to build an interactive client over ZeroMQ, so I've posted it for reference as a standalone github repository.
Shortly thereafter, we had discussions with Eric Jones and Travis Oliphant at Enthought, who offered to support Brian and I to work in collaboration with Evan Patterson, and build a Qt console for IPython using this new design. Our little weekend prototype had been just a proof of concept, but their support allowed us to spend the time necessary to apply the same ideas to the real IPython. Brian and I would build a zeromq kernel with all the IPython functionality, while Evan built a Qt console that would drive it using our communications protocol. This worked extremely well, and by late 2010 we had a more or less complete Qt console working:

Over the summer of 2010, Omar Zapata and Gerardo Gutierrez worked as part of the Google Summer of Code project and started building both terminal- and Qt-based clients for IPython on top of ZeroMQ. Their task was made much harder because we hadn't yet refactored all of IPython to use zmq, but the work they did provided critical understanding of the problem at this point, and eventually by 0.12 much of it has been finally merged.
The value and correctness of this architecture became clear when Brian, Min and I met with the Enthought folks and Shahrokh Mortazavi and Dino Viehland from Microsoft. After a single session explaining to Dino and Shahrokh our design and pointing them to our github repository, they were able to build support for IPython into the new Python Tools for Visual Studio, without ever asking us a single question:

In October 2010 James Gao (a Berkeley neuroscience graduate student) wrote up a quick prototype of a web notebook, demonstrating again that this design really worked well and could be easily used by a completely different client:

And finally, in the summer of 2011 Brian took James' prototype and built up a fully working system, this time using websockets, the Tornado web server, JQuery for Javascript, CodeMirror for code editing, and MathJax for LaTeX rendering. Ironically, we had looked at Tornado in early 2010 along with ZeroMQ as a candidate for our communications, but dismissed it as it wasn't really the tool for that job; it now turned out to be the perfect fit for an asynchronous http server with Websockets support.
We merged Brian's work in late August while working on IRC from a boarding room at the San Francisco airport, just in time for me to present it at the EuroSciPy 2011 conference. We then polished it over the next few months to finally release it as part of IPython 0.12:

Other differences with the Sage notebook
We deliberately wrote the IPython notebook to be a lightweight, single-user program that feels like any other local application. The Sage notebook draws many parallels with the google docs model, by default requiring a login and showing all of your notebooks together, kept in a location separate from the rest of your files. In contrast, we want the notebook to just start like any other program and for the ipynb files to be part of your normal workflow, ready to be version-controlled just like any other, stored in your normal folders and easy to manage on their own. Update: as noted by Jason Grout, the Sage notebook was designed from the start to scale to big centralized multi-user servers (sagenb.org, with about 76,000 accounts, is a good example). The notebook that runs in the local user's computer is the same as the one in these large public servers.
There are other deliberate differences of interface and workflow:
As you see, there are indeed a number of key differences between our notebook and the sage one, but there are very good technical reasons for this. The notebook integrates with our architecture and leverages it; you can for example use the interactive debugger via a console or qtconsole against a notebook kernel, something not possible with the sage notebook.
In addition, Sage is GPL licensed while IPython is BSD licensed. This means we can not directly reuse their code, though when we have asked them to relicense specific pieces of code to us, they have always agreed to do so. But large-scale reuse of Sage code in IPython is not really viable.
The value of being the slowest in the race
As this long story shows, it has taken us a very long time to get here. But what we have now makes a lot of sense for us, even considering the existence of the Sage notebook and how good it is for many use cases. Our notebook is just one particular aspect of a large and rich architecture built around the concept of a Python interpreter abstracted over a JSON-based, explicitly defined communications protocol. Even considering purely http clients, the notebook is still just one of many possible: you can easily build an interface that only evaluates a single cell with a tiny bit of javascript like the Sage single cell server, for example.
Furthermore, since Min also reimplemented our parallel machinery completely with pyzmq, now we have one truly common codebase for all of IPython. We still need to finish up a bit of integration between the interactive kernels and the parallel ones, but we plan to finish that soon.
In many ways, our slow pace of development paid off:
What next?
We have a lot of ideas for the notebook, as we want it to be the best possible environment for modern computational work (scientific work is our focus, but not its only use), including research, education and publication, with consistent support for clean and reproducible practices throughout. We are fairly confident that the core design and architecture are extremely solid, and we already have a long list of ideas and improvements we want to make. We are limited only by manpower and time, so please join us on github and pitch in!
Since this post was motivated by questions about Sage, I'd like to emphasize that we have had multiple, productive collaborations with William and other Sage developers in the past, and I expect that to continue to be the case. On certain points that collaboration has already led to convergence; e.g. the new Sage single cell server uses the IPython messaging protocol, after we worked closely with Jason Grout during Sage Days 29 in March 2011 thanks to William's invitation. Furthermore, William's invitations to several Sage Days events, as well as the workshops we have organized together over the years, offered multiple opportunities for collaboration and discussion that proved critical on the way to today's results.
In the future we may find other areas where we can reuse tools or approaches common to Sage and IPython. It is clear to us that the Sage notebook is a fantastic system, it just wasn't the right fit for IPython. I hope this very long post illustrates why, as well as providing some insights into our vision for scientific computing.
Last, but not least
From this post it should be obvious that what today's IPython is the result of the work of many talented people over the years, and I would like to thank all the developers and users who contribute to the project. But it's especially important to recognize the stunning quality and quantity of work that Brian Granger and Min Ragan-Kelley have done for this to be possible. Brian and I did our PhDs together at CU and we have been close friends since then. Min was an undergraduate student of Brian's while he was a professor at U. Santa Clara and the first IPython parallel implementation using Twisted was his senior thesis project; he is now a PhD student at Berkeley (where I work) so we continue to be able to easily collaborate. Building a project like IPython with partners of such talent, dedication, tenacity and generous spirit is a wonderful experience. Thanks, guys!
Please notify me in the comments of any inaccuracies in the above, especially if I failed to credit someone.
For the IPython project this was a major milestone, as we had wanted for years to have such a system, and it has generated a fair amount of interest online. In particular, on our mailing list a user asked us about the relationship between this effort and the well-known and highly capable Sage Notebook. In responding to the question, I ended up writing up a fairly detailed retrospective of our path to get to the IPython notebook, and it seemed like a good idea to put this up as a blog post to encourage discussion beyond the space of a mailing list, so here it goes (the original email that formed the base of this post, in case anyone is curious about the context).
The question that was originally posed by Oleg Mikulchenklo was: What is the relation and comparison between the IPython notebook and the Sage notebook? Can someone provide motivation and roadmap for the IPython notebook as an alternative to the Sage notebook? I'll try to answer that now...
Early efforts: 2001-2005
Let me provide some perspective on this, since it's a valid question that is probably in the minds of others as well. This is a long post, but I'm trying to do justice to over 10 years of development, multiple interactions between the two projects and the contributions of many people. I apologize in advance to anyone I've forgotten, and please do correct me in the comments, as I want to have a full record that's reasonably trustworthy.
Let's go back to the beginning: when I started IPython in late 2001, I was a graduate student in physics at CU Boulder, and had used extensively first Maple, then Mathematica, both of which have notebook environments. I also used Pascal (earlier) then C/C++, but those two (plus IDL for numerics) were the interactive environments that I knew well, and my experience with them shaped my views on what a good system for everyday scientific computing should look like. In particular, I was a heavy user of the Mathematica notebooks and liked them a lot.
I started using Python in 2001 and liked the language, but its interactive prompt felt like a crippled toy compared to the systems mentioned above or to a Unix shell. When I found out about sys.displayhook, I realized that by putting in a callable object, I would be able to hold state and capture previous results for reuse. I then wrote a python startup file to provide these features and some other niceties such as loading Numeric and Gnuplot, giving me a 'mini-mathematica' in Python (femto- might be a better description, in fairness). Thus was my 'ipython-0.0.1' born, a mere 259 lines to be loaded as $PYTYHONSTARTUP.
I also read an article that mentioned two good interactive systems for Python, LazyPython and IPP, not surprisingly also created by scientists. I say this because the natural flow of scientific computing pretty much mandates a solid interactive environment, so while other Python users and developers may like having occasional access to interactive facilities, scientists more or less demand them. I contacted their authors, Nathan Gray and Janko Hauser, seeking to join forces to create IPython; they were both very gracious and let me use their code, but didn't have the time to participate in the effort. As any self-respecting graduate student with a dissertation deadline looming would do, I threw myself full-time into building the first 'real' IPython by merging my code with both of theirs (eventually I did graduate, by the way).
The point of this little trip down memory lane is to show how from the very beginning, Mathematica and its notebooks (and the Maple worksheets before) were in my mind as the ideal environment for daily scientific work. In 2005 we had two Google SoC students and we took a stab at building, using Wx, a notebook system. Robert Kern then put some more work into the problem, but unfortunately that prototype never really became fully usable.
Sage bursts into the scene
In early 2006, William Stein organized the first Sage Days at UCSD and invited me; William and I had been in touch since 2005 as he was using IPython for the Sage terminal interface. I suggested Robert Kern come as well, and he demoed the notebook prototype he had at that point. It was very clear that the system wasn't production ready, and William was already starting to think about a notebook-like system for Sage as well. Eventually he started working on a browser-based system, and by Sage Days 2 in October 2006, as shown by the coding sprint topics, the Sage notebook was already usable.
For Sage, going at it separately was completely reasonable and justified: we were moving slowly and by that point we weren't even convinced the Wx approach would go anywhere. William is a force of nature and was trying to get Sage to be very usable very fast, so building something integrated for his needs was certainly the right choice.
We continued slowly working on IPython, and actually had another attempt at a notebook-type system in 2006-2007. By that point Brian Granger and Min Ragan-Kelley had come on board and we had built the Twisted-based parallel tools. Using this, Min got a notebook prototype working using an SQL/SQLAlchemy backend. We had the opportunity to work on many of these ideas during a workshop on Interactive Parallel Computation that William and I co-organized (along with others). Like Sage, this prototype used a browser for the client but it tried to retain the 'IPython experience', something the Sage notebook didn't provide.
Keeping the IPython experience in the notebook
This is a key difference of our approach and the Sage notebook, so it' worth clarifying what I mean, the key point being the execution model and its relation to the filesystem. The Sage notebook took the route of using the filesystem for notebook operations, so you can't meaningfully use 'ls' in it or move around the filesystem yourself with 'cd', because Sage will always execute your code in hidden directories with each cell actually being a separate subdirectory. This is a perfectly valid approach and has a number of very good consequences for the Sage notebook, but it is also very different from the IPython model where we always keep the user very close to the filesystem and OS. For us, it's really important that you can access local scripts, use %run, see arbitrary files conveniently, etc., as these are routine needs in data analysis and numerical simulation.
Furthermore, we wanted a notebook that would provide the entire IPython experience, meaning that magics, aliases, syntax extensions and all other special IPython features worked the same in the notebook and terminal. The Sage notebook reimplemented some of these things in its own way: they reused the % syntax but it has a different meaning, they took some of the IPython introspection code and built their own x?/?? object introspection system, etc. In some cases it's almost like IPython but in others the behavior is fairly different; this is fine for Sage but doesn't work for us.
So we continued with our own efforts, even though by then the Sage notebook was fairly mature. For a number of reasons (I honestly don't recall all the details), Min's browser-based notebook prototype also never reached production quality.
Breaking through our bottleneck and ZeroMQ
Eventually, in the summer of 2009 we were able to fund Brian to work full-time on IPython, thanks to Matthew Brett and Jarrod Millman, with resources from the NiPy project. Brian could then dig into the heart of the beast, and attack the fundamental problem that made IPython development so slow and hard: the fact that the main codebase was an outgrowth of that original merge from 2001 of my hack, IPP and LazyPython, by now having become an incomprehensible and terribly interconnected mess with barely any test suite. Brian was able to devote a summer full-time to dismantling these pieces and reassembling them so that they would continue to work as before (with only minimal regressions), but now in a vastly more approachable and cleanly modularized codebase.
This is where early 2010 found us, and then zerendipity struck: while on a month-long teaching trip to Colombia I read an article about ZeroMQ and talked to Brian about it, as it seemed to provide the right abstractions for us with a simpler model than Twisted. Brian then blew me away, coming back in two days with a new set of clean Cython-based bindings: we now had pyzmq! It became clear that we had the right tools to build a two-process implementation of IPython that could give us the 'real IPython' but communicating with a different frontend, and this is precisely what we wanted for cleaner parallel computing, multiprocess clients and a notebook.
When I returned from Colombia I had a free weekend and drove down from Berkeley to San Luis Obispo. Upon arriving at Brian's place I didn't even have zeromq installed nor had I read any docs about it. I installed it, and Brian simply told me what to type in IPython to import the library and open a socket, while he had another one open on his laptop. We then started exchanging messages from our IPython sessions. The fact that we could be up and running this fast was a good sign that the library was exactly what we wanted. We coded frantically in parallel: one of us wrote the kernel and the other the client, and we'd debug one of them while leaving the other running in the meantime. It was the perfect blend of pair programming and simultaneous development, and in just two days we had a prototype of a python shell over zmq working, proving that we could indeed build everything we needed. Incidentally, that code may still be useful to someone wanting to understand our basic ideas or how to build an interactive client over ZeroMQ, so I've posted it for reference as a standalone github repository.
Shortly thereafter, we had discussions with Eric Jones and Travis Oliphant at Enthought, who offered to support Brian and I to work in collaboration with Evan Patterson, and build a Qt console for IPython using this new design. Our little weekend prototype had been just a proof of concept, but their support allowed us to spend the time necessary to apply the same ideas to the real IPython. Brian and I would build a zeromq kernel with all the IPython functionality, while Evan built a Qt console that would drive it using our communications protocol. This worked extremely well, and by late 2010 we had a more or less complete Qt console working:
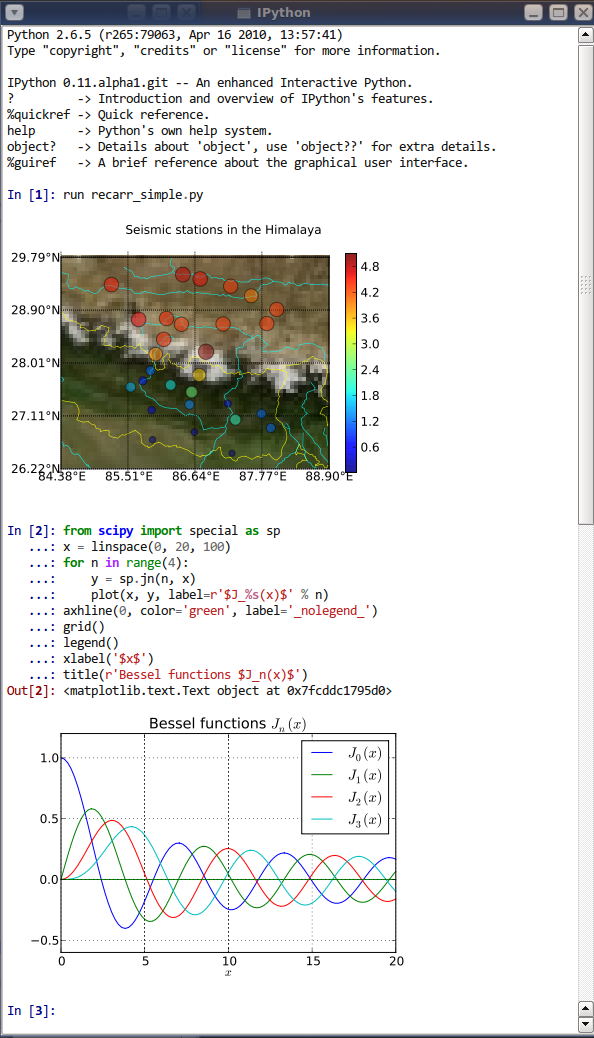
Over the summer of 2010, Omar Zapata and Gerardo Gutierrez worked as part of the Google Summer of Code project and started building both terminal- and Qt-based clients for IPython on top of ZeroMQ. Their task was made much harder because we hadn't yet refactored all of IPython to use zmq, but the work they did provided critical understanding of the problem at this point, and eventually by 0.12 much of it has been finally merged.
The value and correctness of this architecture became clear when Brian, Min and I met with the Enthought folks and Shahrokh Mortazavi and Dino Viehland from Microsoft. After a single session explaining to Dino and Shahrokh our design and pointing them to our github repository, they were able to build support for IPython into the new Python Tools for Visual Studio, without ever asking us a single question:

In October 2010 James Gao (a Berkeley neuroscience graduate student) wrote up a quick prototype of a web notebook, demonstrating again that this design really worked well and could be easily used by a completely different client:

And finally, in the summer of 2011 Brian took James' prototype and built up a fully working system, this time using websockets, the Tornado web server, JQuery for Javascript, CodeMirror for code editing, and MathJax for LaTeX rendering. Ironically, we had looked at Tornado in early 2010 along with ZeroMQ as a candidate for our communications, but dismissed it as it wasn't really the tool for that job; it now turned out to be the perfect fit for an asynchronous http server with Websockets support.
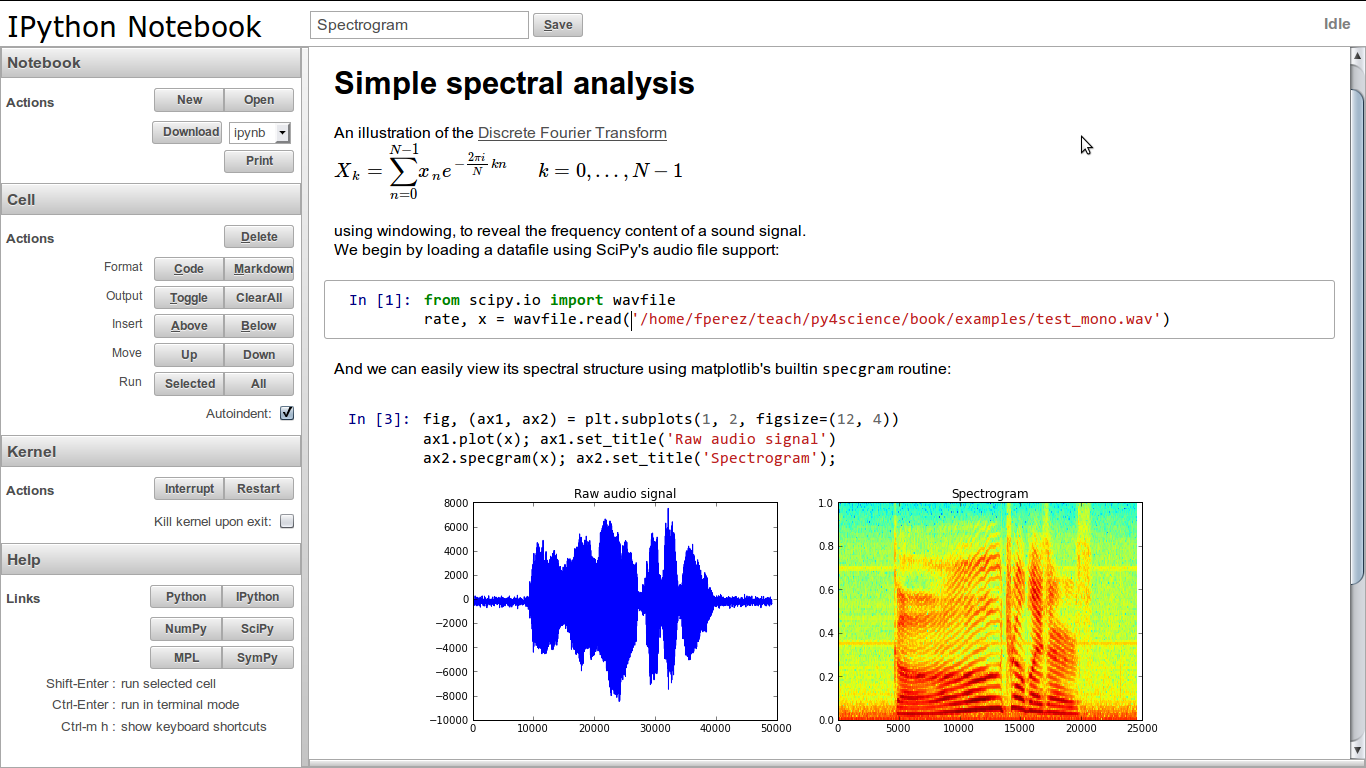
We merged Brian's work in late August while working on IRC from a boarding room at the San Francisco airport, just in time for me to present it at the EuroSciPy 2011 conference. We then polished it over the next few months to finally release it as part of IPython 0.12:
Other differences with the Sage notebook
We deliberately wrote the IPython notebook to be a lightweight, single-user program that feels like any other local application. The Sage notebook draws many parallels with the google docs model, by default requiring a login and showing all of your notebooks together, kept in a location separate from the rest of your files. In contrast, we want the notebook to just start like any other program and for the ipynb files to be part of your normal workflow, ready to be version-controlled just like any other, stored in your normal folders and easy to manage on their own. Update: as noted by Jason Grout, the Sage notebook was designed from the start to scale to big centralized multi-user servers (sagenb.org, with about 76,000 accounts, is a good example). The notebook that runs in the local user's computer is the same as the one in these large public servers.
There are other deliberate differences of interface and workflow:
- We keep our In/Out prompts explicit because we have an entire system of caching variables that uses those numbers, and because those numbers give the user a visual clue of the execution order of cells, which may differ from the document's order.
- We deliberately chose a structured JSON format for our documents. It's clear enough for human reading while allowing easy and powerful machine manipulation without having to write our own parsing. So writing utilities like a reStructuredText or LaTeX converter is very easy, as we recently showed.
- Our move to zmq allowed us (thanks to Thomas Kluyver's tireless work) to ship the notebook working both on Python2 and Python3 out of the box. The current version of the Sage notebook only works on Python2, in part due to its use of Twisted. Update: William pointed out to me that the upcoming 5.0 version of the notebook will have a vastly reduced dependency on Twisted, so this will soon be less of an issue for Sage.
- Because our notebook works in the normal filesystem, and lets you create .py files right next to the .ipynb just by passing --script at startup, you can reuse your notebooks like normal scripts, import one notebook from another or a normal python script, etc. I'm not sure how to import a Sage notebook from a normal python file, or if it's even possible.
- We have a long list of plans for the document format: multi-sheet capabilities, LaTeX-style preamble, per-cell metadata, structural cells to allow outline-level navigation and manipulation such as in LyX, improved literate programming and validation/reproducibility support, ... For that, we need to control the document format ourselves so we can evolve it according to our needs and ideas.
As you see, there are indeed a number of key differences between our notebook and the sage one, but there are very good technical reasons for this. The notebook integrates with our architecture and leverages it; you can for example use the interactive debugger via a console or qtconsole against a notebook kernel, something not possible with the sage notebook.
In addition, Sage is GPL licensed while IPython is BSD licensed. This means we can not directly reuse their code, though when we have asked them to relicense specific pieces of code to us, they have always agreed to do so. But large-scale reuse of Sage code in IPython is not really viable.
The value of being the slowest in the race
As this long story shows, it has taken us a very long time to get here. But what we have now makes a lot of sense for us, even considering the existence of the Sage notebook and how good it is for many use cases. Our notebook is just one particular aspect of a large and rich architecture built around the concept of a Python interpreter abstracted over a JSON-based, explicitly defined communications protocol. Even considering purely http clients, the notebook is still just one of many possible: you can easily build an interface that only evaluates a single cell with a tiny bit of javascript like the Sage single cell server, for example.
Furthermore, since Min also reimplemented our parallel machinery completely with pyzmq, now we have one truly common codebase for all of IPython. We still need to finish up a bit of integration between the interactive kernels and the parallel ones, but we plan to finish that soon.
In many ways, our slow pace of development paid off:
- We had multiple false starts that helped us much to better understand the hard parts of the problem and where the dead ends would lie.
- We were still thinking about this all the time: even when we couldn't spare the time to actively work on it, we had no end of discussions on these things over the years (esp. Brian, Min and I, but also with others at meetings and conferences).
- The Sage notebook was a great trailblazer showing both what could be done, and also how there were certain decisions that we wanted to make differently.
- The technology of some critical third-party tools caught up in an amazing way: ZeroMQ, Tornado, WebSockets, MathJax, and the fast and capable Javascript engines in modern browsers along with good JS libraries. Without these tools we couldn't possibly have implemented what we have now.
What next?
We have a lot of ideas for the notebook, as we want it to be the best possible environment for modern computational work (scientific work is our focus, but not its only use), including research, education and publication, with consistent support for clean and reproducible practices throughout. We are fairly confident that the core design and architecture are extremely solid, and we already have a long list of ideas and improvements we want to make. We are limited only by manpower and time, so please join us on github and pitch in!
Since this post was motivated by questions about Sage, I'd like to emphasize that we have had multiple, productive collaborations with William and other Sage developers in the past, and I expect that to continue to be the case. On certain points that collaboration has already led to convergence; e.g. the new Sage single cell server uses the IPython messaging protocol, after we worked closely with Jason Grout during Sage Days 29 in March 2011 thanks to William's invitation. Furthermore, William's invitations to several Sage Days events, as well as the workshops we have organized together over the years, offered multiple opportunities for collaboration and discussion that proved critical on the way to today's results.
In the future we may find other areas where we can reuse tools or approaches common to Sage and IPython. It is clear to us that the Sage notebook is a fantastic system, it just wasn't the right fit for IPython. I hope this very long post illustrates why, as well as providing some insights into our vision for scientific computing.
Last, but not least
From this post it should be obvious that what today's IPython is the result of the work of many talented people over the years, and I would like to thank all the developers and users who contribute to the project. But it's especially important to recognize the stunning quality and quantity of work that Brian Granger and Min Ragan-Kelley have done for this to be possible. Brian and I did our PhDs together at CU and we have been close friends since then. Min was an undergraduate student of Brian's while he was a professor at U. Santa Clara and the first IPython parallel implementation using Twisted was his senior thesis project; he is now a PhD student at Berkeley (where I work) so we continue to be able to easily collaborate. Building a project like IPython with partners of such talent, dedication, tenacity and generous spirit is a wonderful experience. Thanks, guys!
Please notify me in the comments of any inaccuracies in the above, especially if I failed to credit someone.

Comments
How difficult would be to create a web service based on the ipython notebook, something like sagenb.org?
I am going to use IPython for the next batch I will be teaching. Will keep you posted with my experiences.
Cheers,
Asokan Pichai
And please do keep us posted on how it goes if you use it in teaching or your own research!
@Ondrej: glad to hear it's working out for you, even though we do know there's still much to do. Creating a multiuser service is certainly doable, we just have been focusing first on getting a really solid local user experience. We have a small team and there's only so much we can do at a time :)
@Yannig: note that I was talking above about an outline navigator *like* the one in LyX, not about integrating IPython into LyX. That is another idea altogether, and one that I've also thought about. I hope at some point to have the time to discuss it with the LyX devs.
My first 'real' open source contribution was a Perl script called 'lyxport' to export LyX files to html/pdf back when it didn't work very well in LyX itself, so I have a special sport for LyX (in addition to loving it as a tool). I'd love to have more contact with them again!
A real ipython/lyx integration is technically fairly straightforward now that we have the full zmq protocol. So hopefully an enterprising LyX dev will jump in and just get it done in a weekend :)
Thank you for the clarification. I think that I was understanding what I wanted to rather than what was actually written. Unfortunately I don't have the skills to integrate Ipython into Lyx so I will have to wait patiently for somebody to do so.
Nevertheless thank you for the writeup and for providing ipython to us all.
Regards
Yannig
Thank you very very much for the time spent on this article. I now clearly understand the difference between Sage notebook and IPython, although wish they would become closely interconnected.
I love Sage and IPython from the very begging!
One thing - you wrote in this line:
"The Sage notebook took the route of using the filesystem for notebook operations, so you can't meaningfully use 'ls' in it or move around the filesystem yourself with 'cd', because Sage will always execute your code in hidden directories with each cell actually being a separate subdirectory."
Did you mean to say "The Sage notebook (never) took the route ..." ?
.
Now I think the notebooks are amazing. Wonderful job.
Regarding reproducibily, you probably know about madagascar. I have looked at it, but not being at ease with python, I am scared of tackling Scons scripts...
I feel both ipython and madagascar are working in parallel tracks, since the problems are very similar.
Last, but not least, congrats to the team (past and present).